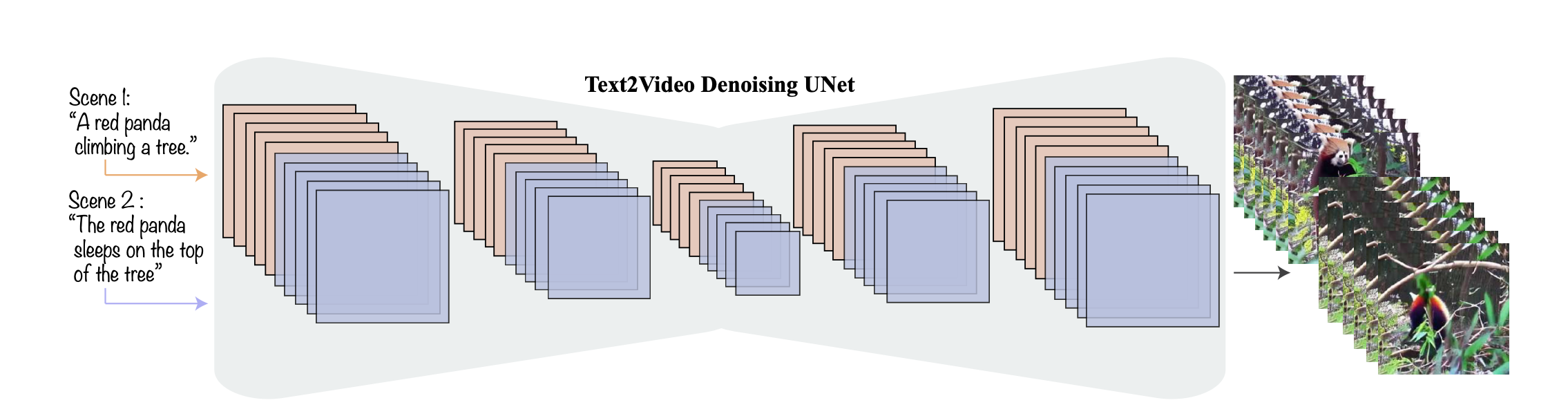
We show the efficacy of TALC in multi-scene video generation by utilizing two models: ModelScope and Lumiere.
We show two settings, one where TALC is applied to the base model during inference and one where we finetune Modelscope on the curate multi-scene video data with TALC framework.
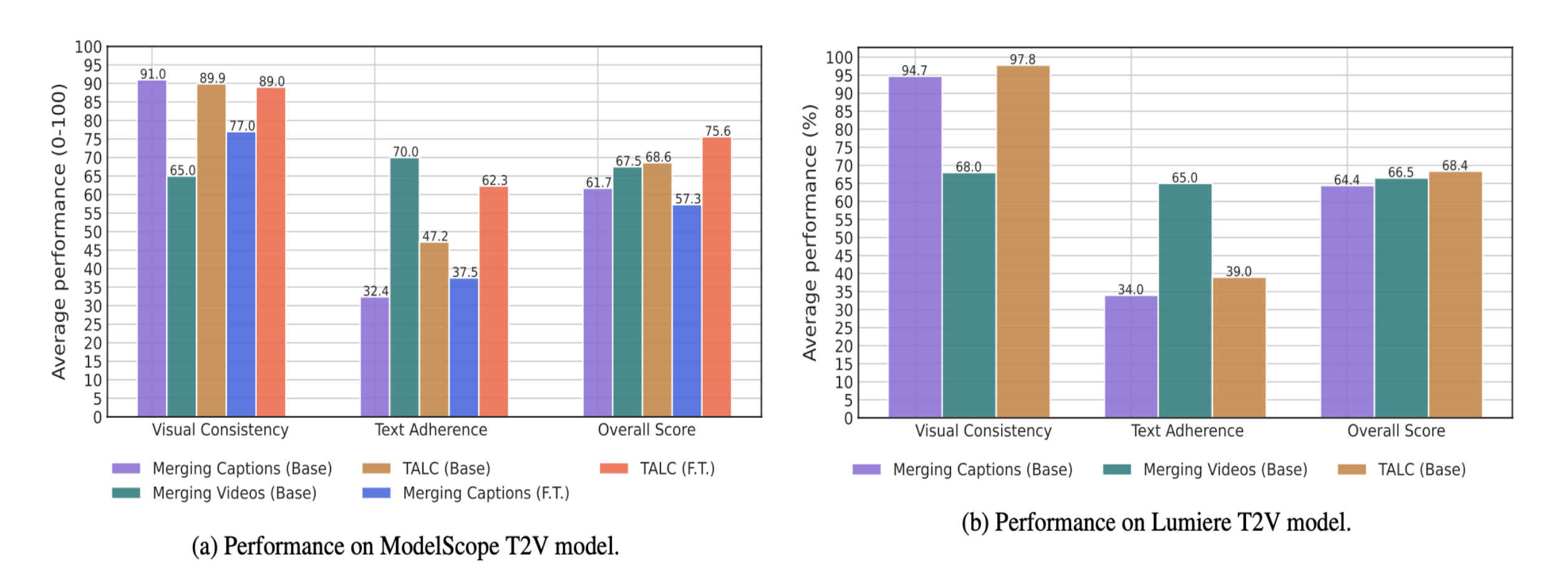
TALC outperforms the baselines without any finetuning
Figure 4(a) and 4(b) show that the base ModelScope and Lumiere with TALC achieves the highest overall scores in multi-scene video generation, outperforming other methods such as merging captions and merging videos.
TALC and merging captions excel in visual consistency, whereas merging videos struggle with maintaining consistent visual elements across scenes. TALC also leads in text adherence, demonstrating its effectiveness
in aligning closely with scene-specific descriptions, unlike merging videos which, while high in text adherence, fail to integrate descriptions across multiple scenes effectively.
This indicates that TALC is particularly effective in producing coherent and textually consistent multi-scene videos.
Finetuning with TALC achieves the best performance.
The ModelScope T2V model was finetuned using the TALC framework and merging captions method to improve performance on multi-scene video-text data.
The finetuning led to TALC achieving the highest overall score, maintaining strong visual consistency while significantly enhancing text adherence.
Conversely, finetuning with merging captions resulted in a notable decrease in visual consistency.
This suggests that finetuning on multi-scene data predominantly benefits text adherence, particularly when using the TALC approach.